IA Cart Pole - contrôle d’équilibre en Intelligence Artificelle
 Ceci est encore un exemple de machine learning qu’un Raspberry pi encaisse sans broncher: il s’agit de contrôler l’équilibre d’un bâton tenu à la verticale sur un axe, à l’aide d’une intelligence artificielle qui va apprendre toute seule à tenir l’équilibre avec un algorithme d’apprentissage neuronal par renforcement, c’est exactement le même principe que le Flappy bird qui apprend à jouer tout seul.
Ceci est encore un exemple de machine learning qu’un Raspberry pi encaisse sans broncher: il s’agit de contrôler l’équilibre d’un bâton tenu à la verticale sur un axe, à l’aide d’une intelligence artificielle qui va apprendre toute seule à tenir l’équilibre avec un algorithme d’apprentissage neuronal par renforcement, c’est exactement le même principe que le Flappy bird qui apprend à jouer tout seul.
Règles du jeux
Elle sont simples: le bâton est initialisé au centre de son axe avec un angle et une vitesse de rotation, et il est soumis aux lois de la gravitation et de la cinématique. Pour le maintenir en équilibre il faut bouger sa masse en bas vers la droite ou la gauche, sur son axe horizontal fixe. Si le dispositif sort de l’écran, ou si le bâton prend un angle de +/- 15° par rapport à la verticale: il a perdu et recommence au milieu. Chaque déplacement réussi fait gagner +1 point, et au bout de 200 points la partie est gagnée.
Cet environnement est disponible avec la bibliothèque python GYM Open AI qui fourni plein d’environnements variés avec lesquels on peut tester des modèles d’apprentissage neuronal par renforcement, et l’installation sur un Raspberry pi ne pose aucun problème, couplé à TensorFlow par exemple. L’environnement que j’ai utilisé est le “CartPole”.
Dans mon programme j’ai mis en oeuvre deux CartPole:
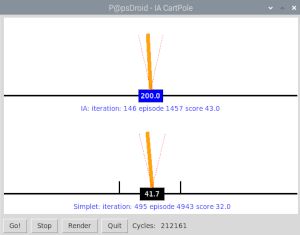
- celui du dessous (masse noire) est contrôlé par un agent simple qui dirige la masse noire là où le bâton penche pour tenter de rattraper l’équilibre.
- celui du dessus (masse bleue) est contrôlé par Intelligence Artificielle via un algorithme neuronal par renforcement.
A vrai dire c’est un univers où la décision à prendre est binaire (pousser vers la gauche ou pousser vers la droite), et l’observation de l’environnement est facile à décrire: la position sur l’axe, la vitesse de la masse, l’inclinaison du bâton et sa vitesse de rotation: un petit réseau de neurones suffit (4 neurones en entrée pour capter les données, 4 en couche cachées, et 1 en sortie pour la prise de décision droite/gauche): ça fera parfaitement l’affaire sur un Raspberry pi.
Interface sous tkinter
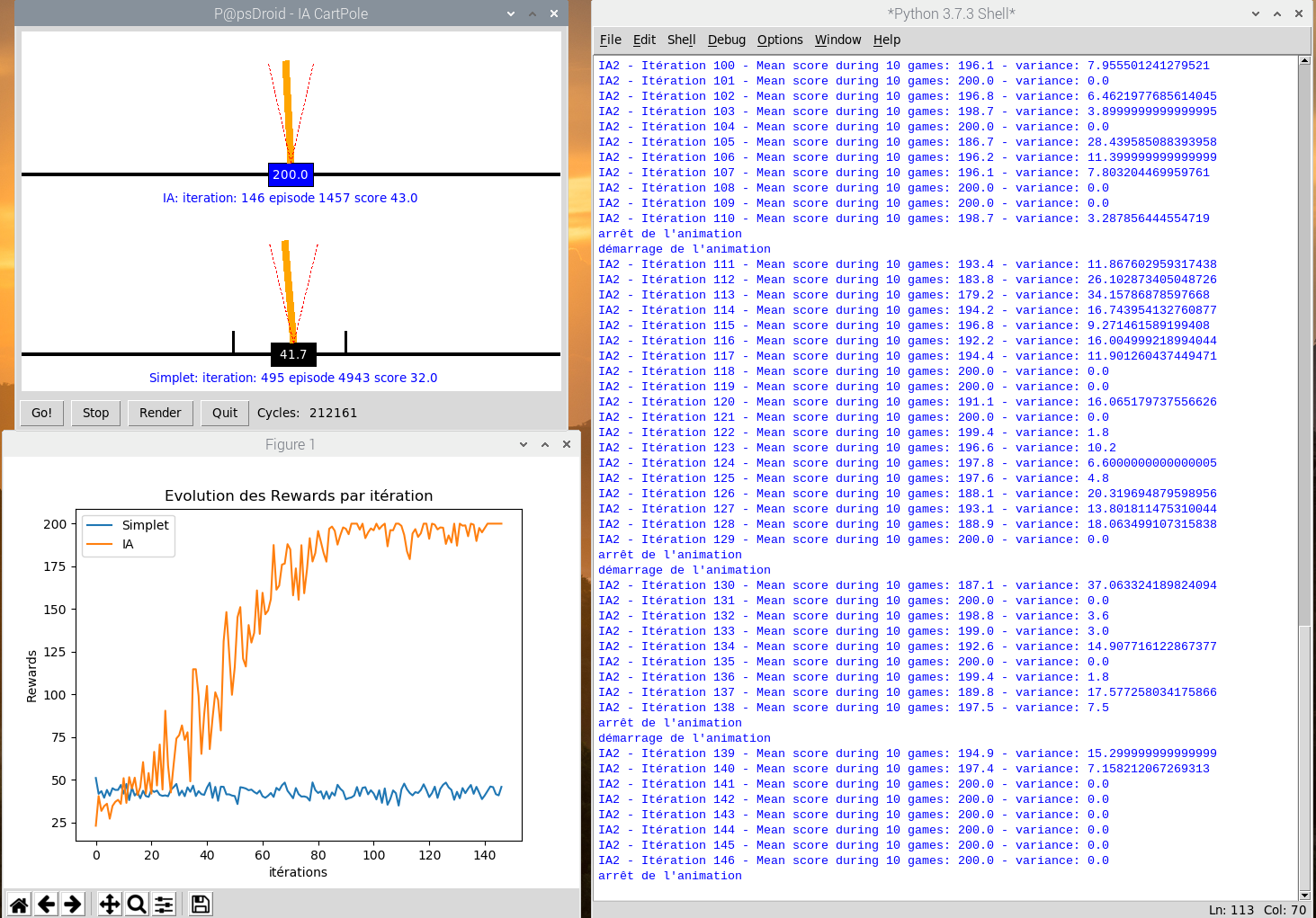
L’interface va permettre de lancer/stopper la partie (Go! / Stop), de supprimer le rafraîchissement écran (Render) ce qui permet d’accélérer considérablement l’apprentissage. Un graphique des rewards moyen par itération (une itération = 10 parties consécutives) est construit au fur et à mesure. Enfin j’affiche régulièrement sous forme texte les rewards moyens et la variance à chaque itération de 10 parties.
Résultat de l’apprentissage sur un Raspberry pi 4
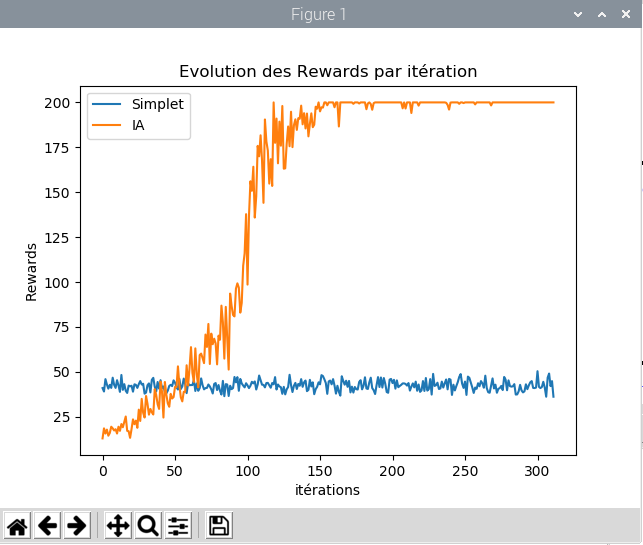
La courbe bleue est celle du “simplet” qui ne fait que bouger dans la direction où le bâton penche. En fait il ne maîtrise absolument ni la vitesse de la masse, ni celle que prend le bâton et n’exploite pas du tout le terrain dont il dispose. On voit clairement qu’il peine à faire plus de 50 points sans faire preuve de la moindre adaptation. En fait ça paraît naturel de se dire je pousse dans la direction où le bâton tombe: mais en faisant cela on oublie que plus on pousse et plus la masse prend de la vitesse ainsi que la bâton: tout s’emballe et le contre-coup et vite irrécupérable, car avant de pouvoir inverser la poussée il faut d’abord pouvoir l’annuler…
C’est là qu’un algorithme d’apprentissage neuronal par renforcement a toute sa place: au lieu de coder avec un nombre incalculable de IF THEN ELSE toutes les situations possibles et imaginables pour rattraper l’équilibre dans telle ou telle condition: laissons la machine découvrir le meilleur moyen et elle va y parvenir sans problème! Il faut compter entre 100 et 150 itérations pour y parvenir, et 300 itérations pour réduire la variance à zéro: elle gagne à tous les coups.
Il faut compter environ 20mn (en ayant appuyé sur RENDER pour neutraliser l’affichage) sur un Raspberry pi 4 pour arriver à 300 itérations. Lorsque l’affichage est activé forcément ça prend beaucoup plus de temps à cause des time.sleep(xx) qui permettent un affichage fluide et lisible: c’est très rapide, bien plus que d’apprendre au Flappy bird à passer à travers 20 barrières … Comme le réseau de neurones est initialisé au hasard, il se comporte très mal au début et fait moins bien que le simplet qui a une petite intelligence codée en dur. Mais il s’améliore vite et surpasse le simplet au bout de 30 à 50 itérations et fonce vers la victoire en 100 ou 150 itérations. Le nombre d’itérations total nécessaire pour le faire converger vers 200 points diffère car il est initialisé complètement au hasard dès le départ. Chaque exécution donnera une courbe d’apprentissage différente.
Programmes python
Vous pouvez télécharger le programme écrit en python3 directement sur ma page Guithub.
Ne pas oublier que les bibliothèques python suivantes sont nécessaires (et il faut utiliser pip3 et non pas pip “tout court” pour installer les packages python3)
- open AI GYM (bibliothèque d’environnement virtuels): exécuter en ligne de commande pip3 install gym
- tkinter (interface graphique): fait déjà partie des packages python3
- numpy (vectorisation et manipulation de tableaux): pip3 install numpy
- matplotlib (générateur de graphiques): pip3 install matplotlib
- tensorflow (voir sur ce billet comment l’installer sur un Raspberry pi)
A noter que j’ai installé mon système sur une SDcard 32Go, mes données sont gérées sur un DD externe SSD 500Go. Ma SD card est utilisée à 54% environ, donc il n’est pas recommandé de faire fonctionner ce programme et toutes les bibliothèques dont il a besoin avec une SD card de 16Go: pas sûr qu’il y ait assez de place…
Pour en savoir plus
Si les notions mathématiques de variance, de distribution normalisée, probabilités, d’équations différentielles, dérivée partielles aux limites, calcul matriciels, et autres descente de gradients dans un référentiel mutli-dimensionnel ne vous effraient pas trop, je vous recommande ces deux lectures qui permettent de bien comprendre le modèle mathématique qui se cache derrière un réseau de neurones (il n’y a pas de magie, ce ne sont que des maths!)
- An introduction to Neural Networks, de Kevin Gurney, éditions CRC Press
- Hands-On Machine Learning with Scikit-Learn and TensorFlow, d’Aurélien Géron (un Français!) aux éditions O’eilly